
Flink基本篇
第一章 初识Flink
实时处理和离线处理
| 处理方式 | 离线计算 | 流式计算 |
|---|---|---|
| 数据加载方式 | 预先加载 | 实时加载 |
| 数据计算范围 | 批量历史数据 | 单条或几条一批的少量最近时效的数据 |
| 时效性 | 数小时级别延迟 | 秒级甚至毫秒级延迟 |
| 计算复杂度 | 复杂的计算逻辑 | 相对简单的计算逻辑,需在时效性和复杂度二者之中权衡 |
| 是否可重复计算 | 可回倒数据至有效存储时间的任意时间点重复计算 | 由于流式数据保留有效期较短,可回到短期有效存储时间的任意时间点重复计算 |
| 修改计算规则成本 | 相对较低 | 相对较高 |
Flink流处理简介
在流式处理中,Flink经常会从Kafka读取流数据,这也是应用最为广泛的组合,Kafka源源不断的向Flink输送数据,Flink处理数据在输送给各种数据库
flink的特点
低延迟
高吞吐
语义化窗口
高容错
易用的API
Flink是什么
Flink是一个大数据处理框架(处理引擎),Flink做的是流处理,Spark做的是批处理.
flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算
有界可以按时间划分有界,也可以按数据量划分有界。
flink是数据处理框架的代表
突出一个快速和灵巧
内存级别的响应速度,可扩展性很好。
flink框架处理流程
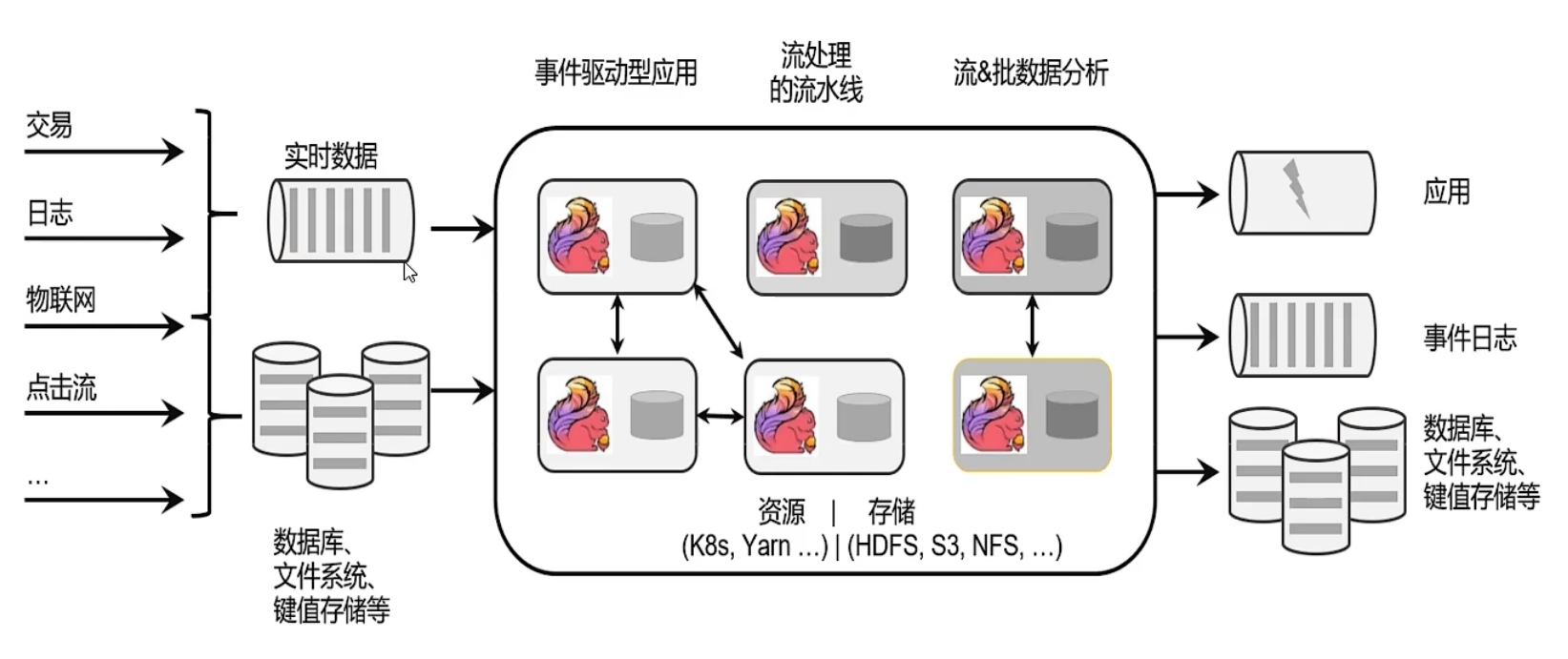
flink要做的就是从外部把数据读取进来,然后做各种类型的处理。
这个处理的过程是实时的,每来一个新的数据,都可以进行处理,并可以把结果返回给应用作为一个响应,也可以将处理结果写入事件日志等。
所以简单来看,这就像一个管道一样,pipeline,有一个数据源,数据源进来之后进行实时的处理,只要不断有数据进来,这些数据都能得到实时的处理。
左边数据进,右边数据出,从不同的数据存储介质里面读取数据,那么也可以将处理之后的数据写入不同的存储介质。
这就是flink的一个大概应用过程。
flink在多种场景都可以使用,只要数据源是实时的,或者业务需要对数据进行实时处理!
flink的应用场景:
- 电商:
- 实时报表
- 实时推荐
- 订单状态跟踪
- 信息推送
- 物联网:
- 实时数据采集
- 实时告警
- 银行和金融业
- 实时结算
- 风险检测
实时数据处理在国内的场景太多了。比较典型的,比如一单实时的交易订单,完成之后,这就是实时数据,必须得到实时的处理,有实时的响应返回给应用,紧跟着有对应的消息下发给用户。
比如物流配送,是要实时地追踪物流订单的状态的。
如果数据量小,那么几台服务器部署后端服务,就可以搞定,但是海量的数据,就需要用上flink这个分布式实时计算框架了。
- 电商:
为什么要用Flink
flink是流处理
真实的业务场景下,更多的是需要流式的处理(需要数据被实时地处理),数据都是像流一样一条条的,这样的场景多,但是数据一批一批的这样的场景也有。
批处理尽管实时性不太好,但是从系统设计和实际经验来看都是比较方便和高效的方式。
所以实时性,低延迟是批处理不具备的。
目标
- 低延迟
- 高吞吐:也就是很快地处理海量数据。处理的数据量既大,处理数据又实时。
- 结果的准确性和容错性(如果发生故障,那么要能够恢复到数据之前的状态)
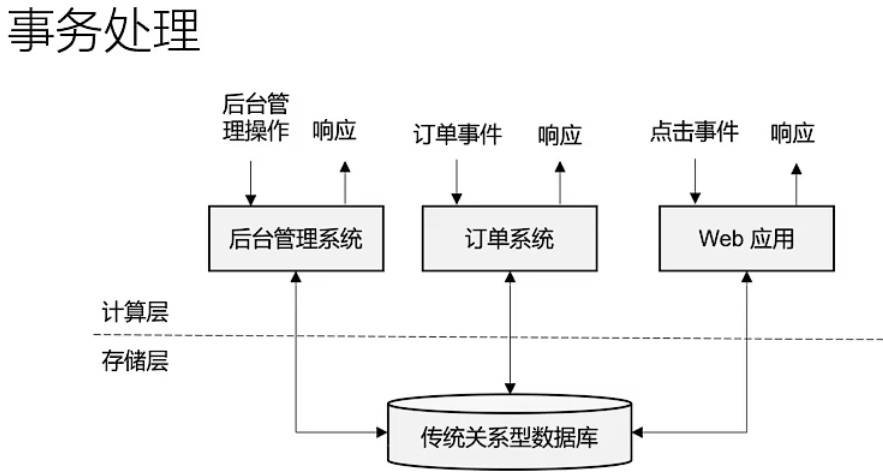
传统数据处理架构
事务处理
所谓计算层就是指的后台服务,这就是传统的web后端服务的架构,接收请求,处理请求,和数据库进行交互,响应给前端。
存储层也不完全是传统关系型数据库,NoSQL也是,比如MongoDB,REDIS内存级别的键值对数据库,Nebula Graph图数据库,ES、Solr这种文档型数据 库,他们所扮演的角色是一样的,就是数据存储层。数据存储层具有最大的一个特点就是数据具有持久性,那么要和数据库进行交互,当请求多,请求量大的时候,会存在响应慢的问题,除了Redis,因为Redis是内存级别的,但是Redis的成本很高。
分析处理
数据量可以非常大,但是是离线的。
而我们现在的目标是低延迟高吞吐,又快数据量又大,不要离线的。既然要快,那么就要借鉴事务处理的架构,来一个就处理一下,如果说用事务处理的架构,关系型数据库变成了一个瓶颈,扩展起来之后速度变慢造价又高,那么现在一个基本的想法就是,直接把远程持久化存储变成一个本地状态,存在内存里面。
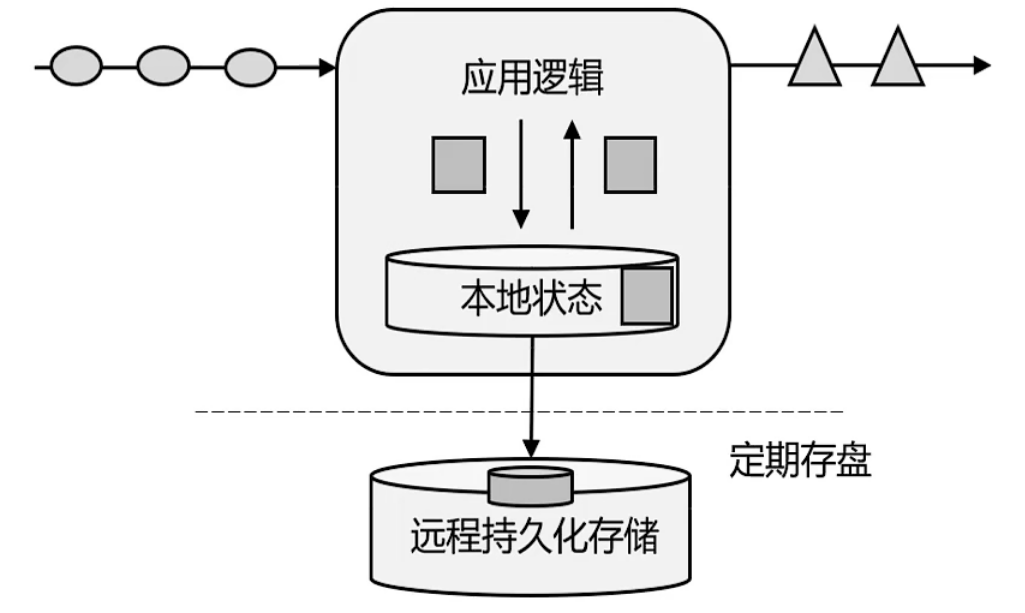
基于这种想法,就有了有状态的流处理这种概念。
仍然是传统的架构,请求来了之后,计算,和存储层交互,但是存储层不使用持久化关系型数据库,而是改成一个本地状态,存储在内存中。和内存中的数据交互比和磁盘交互显然要快很多。
状态存储在内存中会有数据安全问题,所以flink会定期的将本地状态(内存中的状态)存盘,存进持久化数据库中去。---check point
流处理的发展和演变
流处理的演变
lambda架构
用两套系统,同时保证低延迟和结果准确
批处理器需要攒一批数据再处理,这就不够快,但是这能够保证数据的正确性。
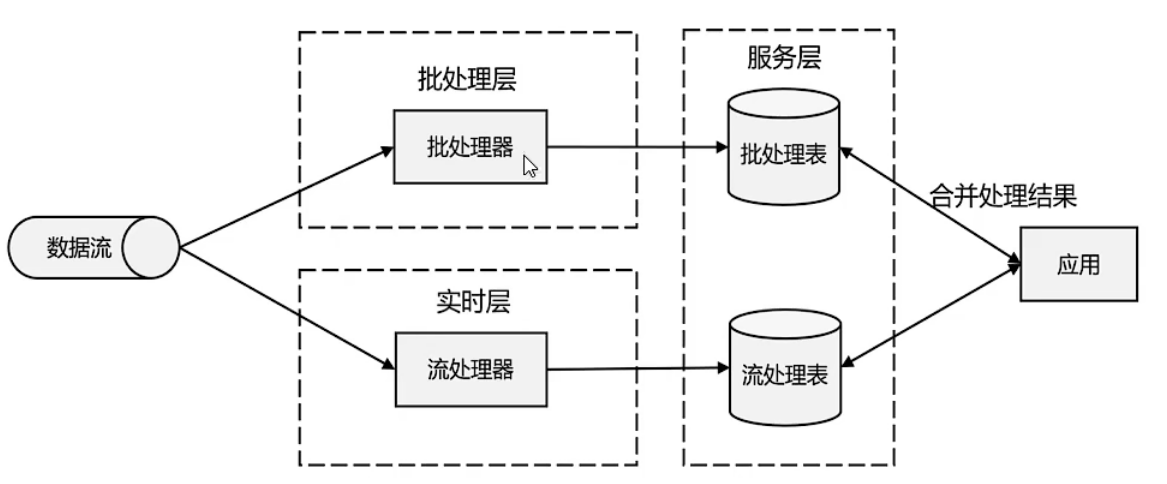
新一代流处理器-Flink
用一套系统把lambda架构的两套功能全都搞定。
同时做到了低延迟和高吞吐。
对于Flink而言,它能够做到每秒钟处理百万级别的数据。
Flink能够保证结果准确性,Flink有事件时间的概念,这个事件时间就可以处理数据乱序。具体放在后面再讲。
架构简图
事件驱动型应用
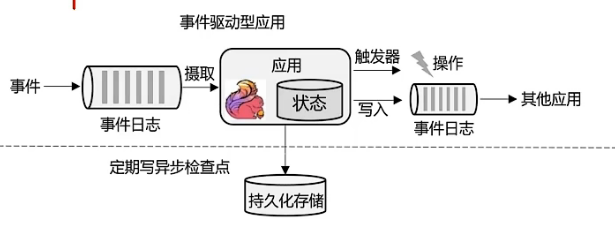
数据源比较常见的是消息队列,所以比较常见的一个架构就是Flink直接去连接消息队列。
flink和kafka的连接是很常见的一种架构。
本地的状态就取代了原先的关系型数据库。
数据分析型应用
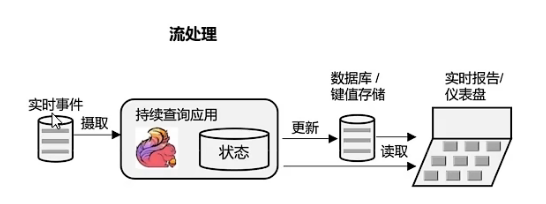
这就是一个实时的分析了。
Flink的主要特点
- 高吞吐
- 低延迟
- 结果准确性
- 精确一次的状态一致性保证---如果发生故障,恢复到故障之前的状态,是完全一致的,就像没有发生故障一样
- 可以与众多常用存储系统连接
- 高可用,支持动态扩展
分层API
整体来讲,Flink API分了四层
越顶层越抽象,表达含义越简明,使用越方便。
越底层越具体,表达能力越丰富,使用越灵活。
SQL--最高层语言
Table API--声明式领域专用语言
DataStream/DataSet--核心API
在1.12版本之后,实现了统一,用DataStream API能做流处理和批处理。
有状态流处理--底层API
Flink与Spark的一些区别
数据处理架构
flink认为批数据是特殊的流,是有界的数据流,这个边界在flink中叫做窗口。
spark认为把批数据切得足够小,就是流了。
数据处理模型
- flink基本数据模型是数据流,以及事件(Event)序列。
- spark采用的是RDD(弹性分布式数据集)模型,spark streaming的DStream实际上也是一组组小批数据RDD的集合。
运行时架构
- spark是批计算,将DAG划分为不同的stage,一个完成后才可以做下一个。
- flink是标准的流执行模式,一个事件(数据)在一个节点处理完后可以直接发往下一个节点进行处理,不用等其他事件或数据,就只跟当前数据和处理有关。
第二章 快速上手
环境准备
Flink底层是用Java编写的,并为开发人员提供了完整的Java和Scala API。
创建Maven项目
引入依赖
properties
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <flink.version>1.13.0</flink.version> <java.version>1.8</java.version> <scala.binary.version>2.12</scala.binary.version> <slf4j.version>1.7.30</slf4j.version> </properties>flink相关依赖
<!--flink相关依赖 --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency>日志管理依赖
<!--日志依赖 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.14.0</version> </dependency>
在properties中,定义了scala.binary.version,这指代的是所依赖的Scala版本。这有一点奇怪:Flink底层是Java,而且我们也只用JavaAPI,为什么还会依赖Scala呢?这是因为Flink的架构中使用了Akka来实现底层的分布式通信,而Akka是用Scala开发的。
批处理
public class BatchWordCount { public static void main(String[] args) { //1. 创建执行环境,flink的执行,是需要有一个复杂的集群,配合起来去做工作的,所以首先要创建执行环境 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //2. 从文件中读取数据,得到了数据源 DataSource<String> dataSource = env.readTextFile("input/words.txt"); //3. 将每行数据进行分词,转换成二元组类型,map是一个通用的转换方法 FlatMapOperator<String, Tuple2<String, Long>> wordTuple = dataSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> { // 收集器Collector也需要泛型,转换输出需要得到的类型是什么,Collector的泛型就写什么类型 // 在这里我们需要得到二元组,即每个单词的频次,那么这个泛型这里就需要写二元组 // 对于Scala来说,本身有元组类型,但是java没有,但是Flink定义了元组类型 // 1.将一行文本进行拆分 String[] words = line.split(" "); // 2. 将每个单词转换成二元组输出 for (String word : words) { out.collect(Tuple2.of(word, 1L)); } }).returns(Types.TUPLE(Types.STRING, Types.LONG)); //4. 按照word进行分组,传入的是Tuple的索引位置,给0表示以索引为0的位置的元素即word来作为分组的key UnsortedGrouping<Tuple2<String, Long>> group = wordTuple.groupBy(0); //5. 分组之后最终是要做统计的 // 分组内进行聚合,叠加 // 指定索引为1的位置的元素做求和的操作 AggregateOperator<Tuple2<String, Long>> sum = group.sum(1); try { sum.print(); } catch (Exception e) { throw new RuntimeException(e); } } }所有的转换操作都是基于DataSet在转换,我们把以上这些调用的API叫做DataSet API,也就是Flink的核心API。
但是从1.12开始,统一使用DataStream API就可以同时实现批处理和流处理。
流处理
介绍
用DataSet API可以很容易地实现批处理,与之对应,流处理当然可以用DataStream API来实现,对于Flink而言,流才是整个底层的核心逻辑,所以流批统一之后的DataStream API更加强大,可以直接处理批处理和流处理的所有场景。
在Flink的视角中,一切数据都可以认为是流,一切数据处理都可以认为是流处理。流数据是无界流,而批数据是有界流。
public class BoundedStreamWordCount { public static void main(String[] args) { //1. 创建流处理的执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2. 读取文件,得到的source,继承自DataStream,所以以下用到的这一套API,叫做DataStream API DataStreamSource<String> source = env.readTextFile("input/words.txt"); //3. 转换计算 SingleOutputStreamOperator<Tuple2<String, Long>> wordTuple = source.flatMap((String line, Collector<Tuple2<String, Long>> out) -> { // 1.将一行文本进行拆分 String[] words = line.split(" "); // 2. 将每个单词转换成二元组输出 for (String word : words) { out.collect(Tuple2.of(word, 1L)); } }).returns(Types.TUPLE(Types.STRING, Types.LONG)); //4. 按照word进行分组,传入的是Tuple的索引位置,给0表示以索引为0的位置的元素即word来作为分组的key KeyedStream<Tuple2<String, Long>, String> tuple2StringKeyedStream = wordTuple.keyBy(data -> data.f0); //5. 分组之后最终是要做统计的 // 分组内进行聚合,叠加 // 指定索引为1的位置的元素做求和的操作 SingleOutputStreamOperator<Tuple2<String, Long>> sum = tuple2StringKeyedStream.sum(1); // 6.打印 // 执行以下这一步是打印不出结果的,是因为这是流处理模式,我们只是当前读取了一个有边界的文件,但是实际上工作模式是流处理,会认为数据是无界的,源源不断会到来的 sum.print(); //7. 启动执行,每来一次数据去执行一次整个的流程,所以会有最后一步执行。 // 把有边界的数据也当作流数据,所以这个地方还没有结束,因为流处理模式认为数据会源源不断到来 // 如果真正流数据来了之后,这个地方还没完呢,还要继续等待数据 try { env.execute(); } catch (Exception e) { throw new RuntimeException(e); } } }结果
7> (flink,1) 5> (world,1) 3> (hello,1) 3> (hello,2) #在之前hello 1的基础上,直接叠加,变成了2 3> (hello,3) 2> (java,1)前面的这个数字就代表了当前是哪个子任务,子任务是按并行度划分的。
flink是分布式流处理引擎,如果在本地启动,会在本地启动多线程模拟分布式环境
flink管最小的资源单位叫任务槽。
并行度就是指当前这个任务通过多线程并行执行,多线程的个数。如果没有设置并行度,那么默认就是当前机器的CPU核心数量。
从socket,也就是通过网络传输读取文本流,后面的处理就是一样的,这里就是数据源不一样。
public class StreamWordCount { public static void main(String[] args) { // 1. 创建流式执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2. 读取一个socket文本流,通过socket发送数据 env.socketTextStream("", 9000); } }从参数中提取主机名和端口号
public class StreamWordCount { public static void main(String[] args) { // 1. 创建流式执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 从参数中提取主机名和端口号 ParameterTool parameterTool = ParameterTool.fromArgs(args); String hostname = parameterTool.get("host"); int port = parameterTool.getInt("port"); //2. 读取一个socket文本流,通过socket发送数据 env.socketTextStream(hostname, port); } }这个parameterTool在哪里去获取参数?
窗口
概念
窗口是将无限数据切割成有限的“数据块”进行处理,窗口是处理无界流的核心。
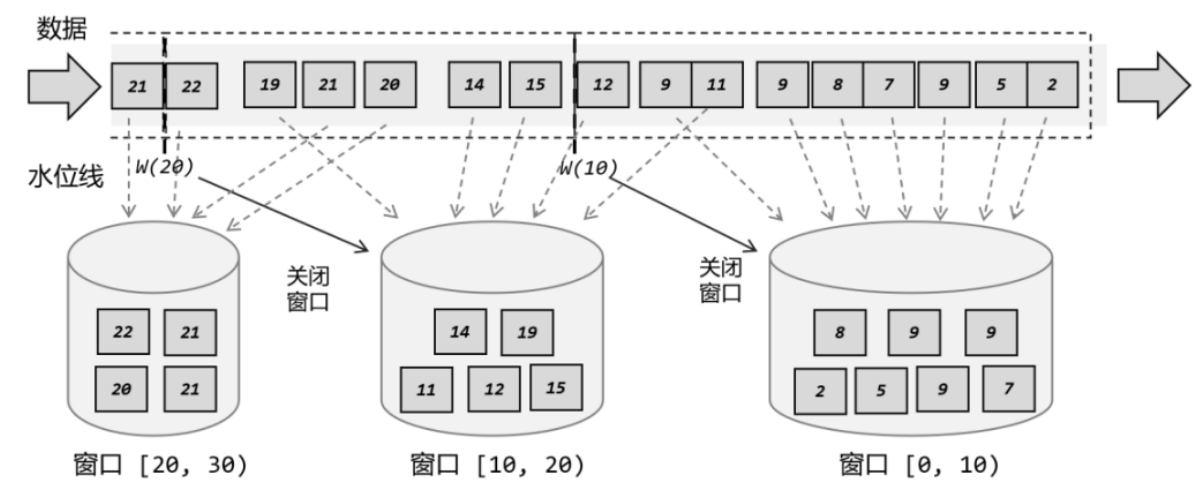
窗口更像一个桶,将流切割成有限大小的多个存储桶,每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
分类
按照驱动类型来分类
以什么标准来开始和结束数据的截取,我们把它叫做窗口的”驱动类型“,常见的有时间窗口和计数窗口。
时间窗口
时间窗口以时间点到来定义窗口的开始(start)和结束(end),所以截取出的就是某一时间段的数据。到达时间时,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁。
Flink中有一个专门的TimeWindow类来表示时间窗口,这个类只有两个私有属性,表示窗口的开始和结束的时间戳,单位为毫秒
窗口时间范围是左闭右开的区间。
计数窗口
基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。
在具体应用时,还需要定义更加精细的规则,来控制数据应该划分到哪个窗口中去。不同的分配数据的方式,就可以由不同的功能应用。
按照窗口分配数据的规则分类
滚动窗口
滚动窗口有固定的大小,首尾相接,无缝衔接,每个数据都会被分配到一个窗口,而且只会属于一个窗口。
滑动窗口
滑动窗口的大小固定,但窗口之间不是首尾相接,而有部分重合。
定义滑动窗口的参数与两个:窗口大小,滑动步长。滑动步长是固定的,且代表了两个个窗口开始/结束的时间间隔。
会话窗口
会话窗口只能基于时间来定义,“会话”终止的标志就是隔一段时间没有数据来。
size:两个会话窗口之间的最小距离。我们可以设置静态固定的size,也可以通过一个自定义的提取器(gap extractor)动态提取最小间隔gap的值。
在Flink底层,对会话窗口有比较特殊的处理:每来一个新的数据,都会创建一个新的会话窗口,然后判断已有窗口之间的距离,
如果小于给定的size,就对它们进行合并操作。在Winodw算子中,对会话窗口有单独的处理逻辑。会话窗口的长度不固定、起始和结束时间不确定,各个分区窗口之间没有任何关联。会话窗口之间一定是不会重叠的,且会留有至少为size的间隔
全局窗口
相同key的所有数据都分配到一个同一个窗口中;无界流的数据永无止境,窗口没有结束的时候,默认不做触发计算,如果希望对数据进行计算处理,还需要自定义“触发器”(Trigger)
窗口API
Keyed
经过按按键分区keyBy操作后,数据流会按照key被分为多条逻辑流(logical streams),也就是KeyedStream。基于KeyedStream进行窗口操作时,窗口计算会在多个并行子任务上同时执行。相同key的数据被发送到同一个并行子任务,而窗口操作会基于每个key单独的处理。可以认为每个key上都定义了一组窗口,各自独立地进行统计计算。
stream.keyBy(...)
.window(...)
Non-keyed
如果没有进行keyBy,那么原始的DataStream就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,相当于并行度变成了1
stream.windowAll(...)
API调用
窗口的操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)
stream.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(<window function>)
窗口分配器
定义窗口分配器是构建窗口算子的第一步,作用是定义数据应该被分配到哪个窗口
除去自定义外的全局窗口外,其它常用的类型Flink都给出了内置的分配器实现
时间窗口又可细分为滑动、滚动和会话三种。
计数窗口可分为滑动和滚动两种。
时间窗口
滚动处理
stream.keyBy(...) .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .aggregate(...).of()还有一个重载方法,可以传入两个Time类型的参数:size和offset。第二个参数代表窗口起始点的偏移量,比如,标志时间戳是1970年1月1日0时0分0秒0毫秒开始计算的一个毫秒数,这个时间时UTC时间,以0时区为标准,而我们所在的时区为东八区(UTC+8)。我们定义一天滚动窗口时,伦敦时间0但对应北京时间早上8点。那么设定如下就可以得到北京时间每天0点开开启滚动窗口
滑动处理
stream.keyBy(...) .window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))) .aggregate(...)两个Time类型的参数:size和slide。后者表示滑动窗口的滑动步长。
会话处理
定义窗口分配,知道数据属于哪个窗口;定义窗口函数,如何进行计算的操作。
Transformations
Flink 的 Transformations 操作主要用于将一个和多个 DataStream 按需转换成新的 DataStream。
DataStream
Map
对一个DataStream中的每个元素都执行特定的转换操作
DataStream<Integer> integerDataStream = env.fromElements(1, 2, 3, 4, 5); integerDataStream.map((MapFunction<Integer, Object>) value -> value * 2).print(); // 输出 2,4,6,8,10FlatMap
与Map类似,但是FlatMap中的一个输入元素可以被映射成一个或多个输出元素
Filter
用于过滤符合条件的数据
KeyBy
用于将相同key值的数据分到相同的分区中
每一次操作(map、flatmap)等都是在新建一个Transformation并将当前Transformation与下一个建立链接的关系。
第三章 Flink工作流程
概述
DataStream(数据流)本身是Flink中一个表示数据集合的类,我们编写的flink代码其实就是基于这种数据类型的处理,可以理解为这就是一套API,对于批处理和流处理,都可以用这同一套API来实现。
我们在代码中并不关心DataStream中具体的数据,而只是用API定义出的一连串操作来处理他们,这就叫做数据流的转换(transformations)。
一个Flink程序,其实就是对DataStream的各种转换
具体来说,代码基本上都由以下几部分组成:
- 获取执行环境
- 读取数据源
- 定义数据的转换操作、数据处理、数据清晰、数据聚合等(transformations)
- 定义计算结果的输出位置(sink)
- 触发执行程序
执行环境
Flink程序可以在各种上下文环境中运行,我们可以在本地JVM中执行程序,也可以提交到远程集群执行
这就要求我们在提交作业执行计算时, 首先必须获取当前 Flink 的运行环境,从而建立起与 Flink 框架之间的联系。只有获取了环境上下文信息,才能将具体的任务调度到不同的 TaskManager 执行。
创建执行环境
最简单的方式,就是直接调用 getExecutionEnvironment方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了 jar 包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境。
执行模式
从1.12.0版本起,Flink实现了API上的流批统一,Datastream API可以支持不同的执行模式
流执行模式
一般用于需要持续实时处理的无界数据流,默认情况下,程序使用的就是流执行模式
批执行模式
对于不会持续计算的有界数据,我们用这种模式处理会更方便。
自动模式
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
通过代码配置batch模式
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
什么时候用batch模式?
我们知道,Flink 本身持有的就是流处理的世界观,即使是批量数据,也可以看作“有界流”来进行处理。所以STREAMING 执行模式对于有界数据和无界数据都是有效的;而 BATCH 模式仅能用于有界数据。
看起来 BATCH 模式似乎被 STREAMING 模式全覆盖了,那还有必要存在吗?我们能不能所有情况下都用流处理模式呢?
当然是可以的,但是这样有时不够高效。
我们可以仔细回忆一下word count 程序中,批处理和流处理输出的不同:在 STREAMING 模式下,每来一条数据,就会输出一次结果(即使输入数据是有界的);而 BATCH 模式下,只有数据全部处理完之后,才会一次性输出结果。最终的结果两者是一致的,但是流处理模式会将更多的中间结果输出。在本来输入有界、只希望通过批处理得到最终的结果的场景下, STREAMING 模式的逐个输出结果就没有必要了。
所以总结起来,一个简单的原则就是:用 BATCH 模式处理批量数据,用 STREAMING 模式处理流式数据。因为数据有界的时候,直接输出结果会更加高效;而当数据无界的时候, 我们没得选择——只有 STREAMING 模式才能处理持续的数据流。
有了执行环境,我们就可以构建程序的处理流程了:基于环境(env)读取数据源(source),从而得到数据流,对数据流(stream)进行各种转换操作(transformations),最后输出结果到外部系统(sink)。
source
graph LR
env --> source --> transform --> sink --> env.execute
source就是我们整个处理程序的输入端。
Flink 代码中通用的添加 source 的方式,是调用执行环境的 addSource()方法:
DataStream<String> stream = env.addSource(...);
方法传入一个对象参数,需要实现SourceFunction 接口;返回DataStreamSource。这里的DataStreamSource类继承自SingleOutputStreamOperator类,又进一步继承自DataStream。所以很明显,读取数据的 source 操作是一个算子,得到的是一个数据流(DataStream)。
从kafka读取数据(重点)
在如今的实时流处理应用中,由 Kafka 进行数据的收集和传输,Flink 进行分析计算,这样的架构已经成为众多企业的首选。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//kafka配置
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", kafkaConfig.getBrokers());
properties.setProperty("group.id", kafkaConfig.getGroupId());
properties.setProperty("key.deserializer", kafkaConfig.getKeyDeserializer());
properties.setProperty("value.deserializer", kafkaConfig.getValueDeserializer());
properties.setProperty("auto.offset.reset", kafkaConfig.getAutoOffsetReset());
//从Kafka获取数据流
DataStreamSource<String> stream = env.addSource(new FlinkKafkaConsumer<String>(
"demo",
new SimpleStringSchema(),
properties
));
stream.print();
try {
env.execute();
} catch (Exception e) {
throw new RuntimeException(e);
}
Transformations
从数据源读入数据之后,我们就可以使用各种转换算子,将一个或多个DataStream转换为新的DataStream,一个Flink程序的核心,其实就是所有的转换操作,他们决定了处理的业务逻辑
基本转换算子
映射(map)
map主要用于将数据流中的数据进行转换,形成新的数据流,一个一个映射,消费一个元素就产出一个元素。
我们只需要基于DataStrema 调用
map()方法就可以进行转换处理。方法需要传入的参数是接口 MapFunction 的实现;返回值类型还是DataStream,不过泛型(流中的元素类型)可能改变。import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class TransMapTest { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<Event> stream = env.fromElements( new Event("Mary", "./home", 1000L), new Event("Bob", "./cart", 2000L) ); // 传入匿名类,实现MapFunction stream.map(new MapFunction<Event, String>() { @Override public String map(Event e) throws Exception { return e.user; } }); // 传入MapFunction的实现类 stream.map(new UserExtractor()).print(); env.execute(); } public static class UserExtractor implements MapFunction<Event, String> { @Override public String map(Event e) throws Exception { return e.user; } } }MapFunction 实现类的泛型类型,与输入数据类型和输出数据的类型有关。
在实现
MapFunction接口的时候,需要指定两个泛型,分别是输入事件和输出事件的类型,还需要重写一个map()方法,定义从一个输入事件转换为另一个输出事件的具体逻辑。Flink消费kafka,数据是json格式的数据
先反序列化,再通过对象清洗数据
SingleOutputStreamOperator<Entity> StreamRecord = env.addSource(consumer) .map(string -> JSON.parseObject(string, Entity.class)) .setParallelism(1); //融合一些transformation算子进来 //map:输入一个元素,输出一个元素,可以用来做一些清洗工作 SingleOutputStreamOperator<Entity> result = StreamRecord.map(new MapFunction<Entity, Entity>() { @Override public Entity map(Entity value) throws Exception { Entity entity1 = new Entity(); entity1.city = value.city+".XPU.Xiax"; entity1.phoneName = value.phoneName.toUpperCase(); entity1.loginTime = value.loginTime; entity1.os = value.os; return entity1; } });过滤(filter)
filter转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为 true 则元素正常输出,若为 false 则元素被过滤掉。// 传入匿名类实现FilterFunction stream.filter(new FilterFunction<Event>() { @Override public boolean filter(Event e) throws Exception { return e.user.equals("Mary"); } });扁平映射(flatMap)
主要是将数据流中的整体(一般是集合类型),拆分成一个一个的个体使用,消费一个元素,可以产生0到多个元素。
同 map 一样,flatMap 也可以使用Lambda 表达式或者 FlatMapFunction 接口实现类的方式来进行传参,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同。
flatMap 操作会应用在每一个输入事件上面,FlatMapFunction 接口中定义了flatMap 方法, 用户可以重写这个方法,在这个方法中对输入数据进行处理,并决定是返回 0 个、1 个或多个结果数据。因此 flatMap 并没有直接定义返回值类型,而是通过一个“收集器”(Collector)来指定输出。希望输出结果时,只要调用收集器的.collect()方法就可以了;这个方法可以多次调用,也可以不调用。所以 flatMap 方法也可以实现 map 方法和 filter 方法的功能,当返回结果是 0 个的时候,就相当于对数据进行了过滤,当返回结果是 1 个的时候,相当于对数据进行了简单的转换操作。
import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class TransFlatmapTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<Event> stream = env.fromElements( new Event("Mary", "./home", 1000L), new Event("Bob", "./cart", 2000L) ); stream.flatMap(new MyFlatMap()).print(); env.execute(); } public static class MyFlatMap implements FlatMapFunction<Event, String> { @Override public void flatMap(Event value, Collector<String> out) throws Exception { if (value.user.equals("Mary")) { out.collect(value.user); } else if (value.user.equals("Bob")) { out.collect(value.user); out.collect(value.url); } } } }
聚合算子
按键分区--keyBy
在 Flink 中,要做聚合,需要先进行分区; 这个操作就是通过
keyBy来完成的。**keyBy 是聚合前必须要用到的一个算子。**keyBy 通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务,也就对应着任务槽。
基于不同的key,流中的数据将被分配到不同的分区中去;这样一来,所有具有相同的key 的数据,都将被发往同一个分区,那么下一步算子操作就将会在同一个 slot 中进行处理了。
import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class TransKeyByTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<Event> stream = env.fromElements( new Event("Mary", "./home", 1000L), new Event("Bob", "./cart", 2000L) ); // 使用 Lambda 表达式 KeyedStream<Event, String> keyedStream = stream.keyBy(e -> e.user); // 使用匿名类实现 KeySelector KeyedStream<Event, String> keyedStream1 = stream.keyBy(new KeySelector<Event, String>() { @Override public String getKey(Event e) throws Exception { return e.user; } }); env.execute(); } }泛型有两个类型:除去当前流中的元素类型外,还需要指定 key 的类型。
keyBy会得到keyedStream,KeyedStream 是一个非常重要的数据结构,只有基于它才可以做后续的聚合操作(比如 sum,reduce)
聚合
有了按键分区的数据流 KeyedStream,我们就可以基于它进行聚合操作了。Flink 为我们内置实现了一些最基本、最简单的聚合API,主要有以下几种:
sum():在输入流上,对指定的字段做叠加求和的操作。
min():在输入流上,对指定的字段求最小值。
max():在输入流上,对指定的字段求最大值。
minBy():与 min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而minBy()则会返回包含字段最小值的整条数据。
maxBy() :与 max() 类似, 在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
简单聚合算子返回的,同样是一个 SingleOutputStreamOperator,也就是从 KeyedStream 又转换成了常规的 DataStream。所以可以这样理解:keyBy 和聚合是成对出现的,先分区、后聚合,得到的依然是一个 DataStream。而且经过简单聚合之后的数据流,元素的数据类型保持不变。
一个聚合算子,会为每一个key 保存一个聚合的值,在Flink 中我们把它叫作“状态”(state)。所以每当有一个新的数据输入,算子就会更新保存的聚合结果,并发送一个带有更新后聚合值的事件到下游算子。对于无界流来说,这些状态是永远不会被清除的,所以我们使用聚合算子, 应该只用在含有有限个key的数据流上。
归约聚合
调用 KeyedStream 的 reduce 方法时,需要传入一个参数,实现 ReduceFunction 接口。
ReduceFunction 接口里需要实现 reduce()方法,这个方法接收两个输入事件,经过转换处理之后输出一个相同类型的事件;所以,对于一组数据,我们可以先取两个进行合并,然后再将合并的结果看作一个数据、再跟后面的数据合并,最终会将它“简化”成唯一的一个数据, 这也就是 reduce“归约”的含义。在流处理的底层实现过程中,实际上是将中间“合并的结果” 作为任务的一个状态保存起来的;之后每来一个新的数据,就和之前的聚合状态进一步做归约。
例子:我们将数据流按照用户 id 进行分区,然后用一个 reduce 算子实现 sum 的功能,统计每个用户访问的频次;进而将所有统计结果分到一组,用另一个 reduce 算子实现maxBy 的功能, 记录所有用户中访问频次最高的那个,也就是当前访问量最大的用户是谁。
import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class TransReduceTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 这里的使用了之前自定义数据源小节中的ClickSource() env.addSource(new ClickSource()) // 将Event数据类型转换成元组类型 .map(new MapFunction<Event, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(Event e) throws Exception { return Tuple2.of(e.user, 1L); } }) .keyBy(r -> r.f0) // 使用用户名来进行分流 .reduce(new ReduceFunction<Tuple2<String, Long>>() { @Override public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception { // 每到一条数据,用户pv的统计值加1 return Tuple2.of(value1.f0, value1.f1 + value2.f1); } }) .keyBy(r -> true) // 为每一条数据分配同一个key,将聚合结果发送到一条流中去 .reduce(new ReduceFunction<Tuple2<String, Long>>() { @Override public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception { // 将累加器更新为当前最大的pv统计值,然后向下游发送累加器的值 return value1.f1 > value2.f1 ? value1 : value2; } }) .print(); env.execute(); } }
自定义函数
lambda
当使用 map() 函数返回 Flink 自定义的元组类型时也会发生类似的问题。下例中的函数签名
Tuple2<String, Long> map(Event value)被类型擦除为Tuple2 map(Event value)。//使用 map 函数也会出现类似问题,以下代码会报错 DataStream<Tuple2<String, Long>> stream3 = clicks .map( event -> Tuple2.of(event.user, 1L) ); stream3.print();解决,多种方式:
// 1) 使用显式的 ".returns(...)" DataStream<Tuple2<String, Long>> stream3 = clicks .map( event -> Tuple2.of(event.user, 1L) ) .returns(Types.TUPLE(Types.STRING, Types.LONG)); stream3.print(); // 2) 使用类来替代 Lambda 表达式 clicks.map(new MyTuple2Mapper()) .print(); // 3) 使用匿名类来代替 Lambda 表达式 clicks.map(new MapFunction<Event, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(Event value) throws Exception { return Tuple2.of(value.user, 1L); } }).print();富函数类
富函数类能获取运行环境的上下文,有生命周期的概念。
import org.apache.flink.api.common.functions.RichMapFunction; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class TransRichFunctionTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(2); DataStreamSource<Event> clicks = env.fromElements( new Event("Mary", "./home", 1000L), new Event("Bob", "./cart", 2000L), new Event("Alice", "./prod?id=1", 5 * 1000L), new Event("Cary", "./home", 60 * 1000L) ); // 将点击事件转换成长整型的时间戳输出 clicks.map(new RichMapFunction<Event, Long>() { @Override public void open(Configuration parameters) throws Exception { super.open(parameters); System.out.println("索引为 " + getRuntimeContext().getIndexOfThisSubtask() + " 的任务开始"); } @Override public Long map(Event value) throws Exception { return value.timestamp; } @Override public void close() throws Exception { super.close(); System.out.println("索引为 " + getRuntimeContext().getIndexOfThisSubtask() + " 的任务结束"); } }) .print(); env.execute(); } }
sink
Flink 的 DataStream API 专门提供了向外部写入数据的方法: addSink。与 addSource 类似,addSink 方法对应着一个“Sink”算子,主要就是用来实现与外部系统连接、并将数据提交写入的;Flink 程序中所有对外的输出操作,一般都是利用 Sink 算子完成的。
第四章 Flink部署
介绍
当我们如上开发的时候,在开发环境里面其实并没有flink集群,是由我们引入的依赖在IDE里面,也就是集成开发环境里面模拟了一个集群,由上面的输出可知,在本地像上面这样开发的时候,分布式计算是由本地启用多线程来处理的。
在实际生产中,应该真正意义上启动一个集群,把想要运行的作业、项目,打包好提交上去。
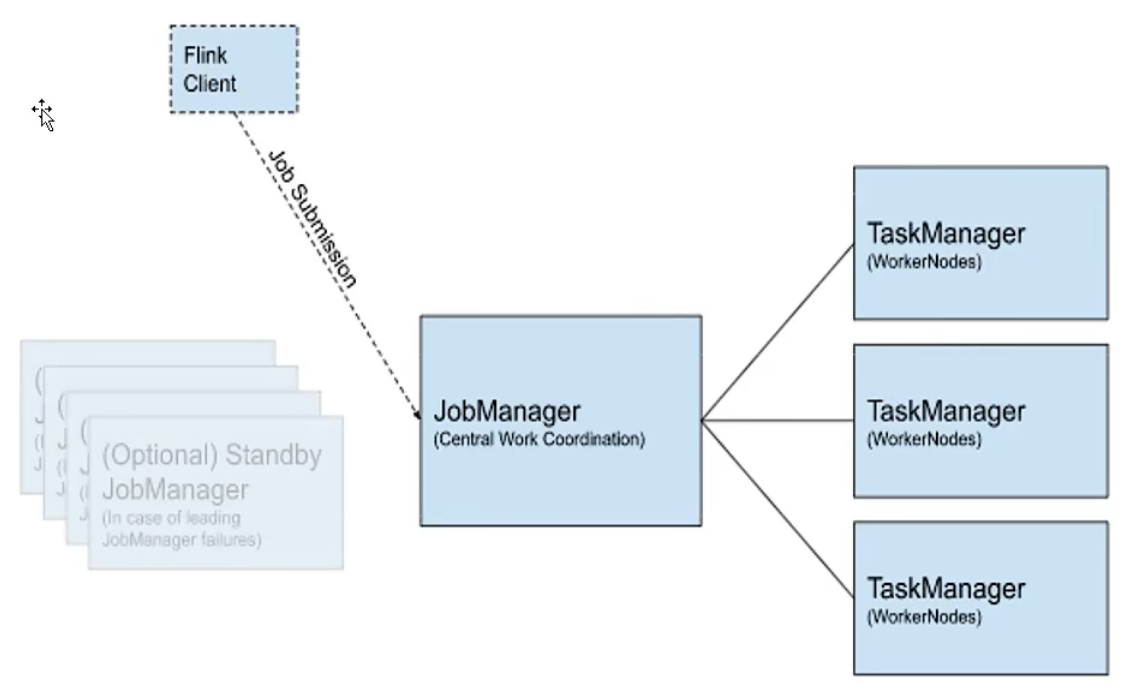
flink提交作业和执行任务,需要几个关键组件:
- 客户端--client
- 作业管理器--JobManager
- 任务管理器--TaskManager
我们的代码由客户端获取并做转换,之后提交给JobManager。JobManager是对作业进行中央调度管理的。
JobManager获取到作业后,会进一步处理转换,然后分发任务给众多的TaskManager,这里的TaskManager,就是真正“干活的人”,数据的处理操作都是他们来做的。
单机部署
官网下载flink-1.13.0-bin-scala_2.12.tgz
上传文件到服务器
解压缩
修改配置文件
修改conf/flink-conf.yml文件
修改jobmanager.rpc.address字段的值为服务器地址。
修改masters
masters和workers有主从关系的意思,jobManager是分发任务的,TaskManager是执行任务的,也就是干活的,masters就是当前的JobManager,就配置当前的JobManager的地址和端口。
这里的端口是可以访问的web服务的端口号。
修改workers为执行任务的服务器地址
启动
执行启动命令
bin/start-cluster.sh查看进程
jps
flink-conf 配置
jobmanager.memory.process.size
给jobmanager分配的内存的大小,默认是1600M。
taskmanager.memory.process.size
给jobmanager分配的内存的大小,默认是1728M。
taskmanager.numberOfTaskSlots
任务槽,有几个任务槽就可以并行执行几个任务。默认是1,就是默认只能执行1个任务
parallelism.default
并行度。
向集群提交作业
web UI
上传作业
上传的是打包好的项目,即jar包

指定作业的执行入口 EntryClass

命令行
./bin/flink run xxx.jar
通过web提交需要输入的参数,通过命令行实现:
./flink run -c com.atguigu.wc.StreamWordCount -p 1 ../FlinkTutorial-1.0-SNAPSHOT.jar
取消任务,释放资源(需要指定jobId):
[root@xx bin]# ./flink cancel 9869b083511c0b9910b494faadbdf509
Cancelling job 9869b083511c0b9910b494faadbdf509.
Cancelled job 9869b083511c0b9910b494faadbdf509.
任务槽就相当于是资源,当资源数为0时,再去提交作业,就会报错。
部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求,flink为各种场景提供了不同的部署模式。
- 会话模式
- 单作业模式
- 应用模式
他们的区别主要在于:集群的生命周期以及资源的分配方式,以及应用的main方法到底在哪里执行,客户端还是jobmanager。
会话模式
会话模式其实最符合常规思维,我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。