
kafka
一、概述
定义
Kafka传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
传统的消息队列的主要应用场景:缓冲/削峰、解耦、异步通信。
缓冲、削峰:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
解耦:想把数据传到大数据处理引擎,数据的来源有多种,例如MySQL、Flume等,数据的接收端也有多种,比如hadoop、flink,kafka的解耦特性允许我们分别在生产端和消费端独立进行数据的处理,只要保证数据遵守同样的接口约束。
例如数据的来源是CPU采集数据,或者文件,那么接收端是MySQL或者es等,中间需要kafka来进行缓冲,因为数据和文件要推送到oss进行分析,而只需要把文件信息写入kafka,文件的分析通常较慢,这样消费端要花的时间更多,这样就进行了缓冲,解决了消费端和生产端速率不一致的问题。
解耦指的是解生产端和消费端的耦合。
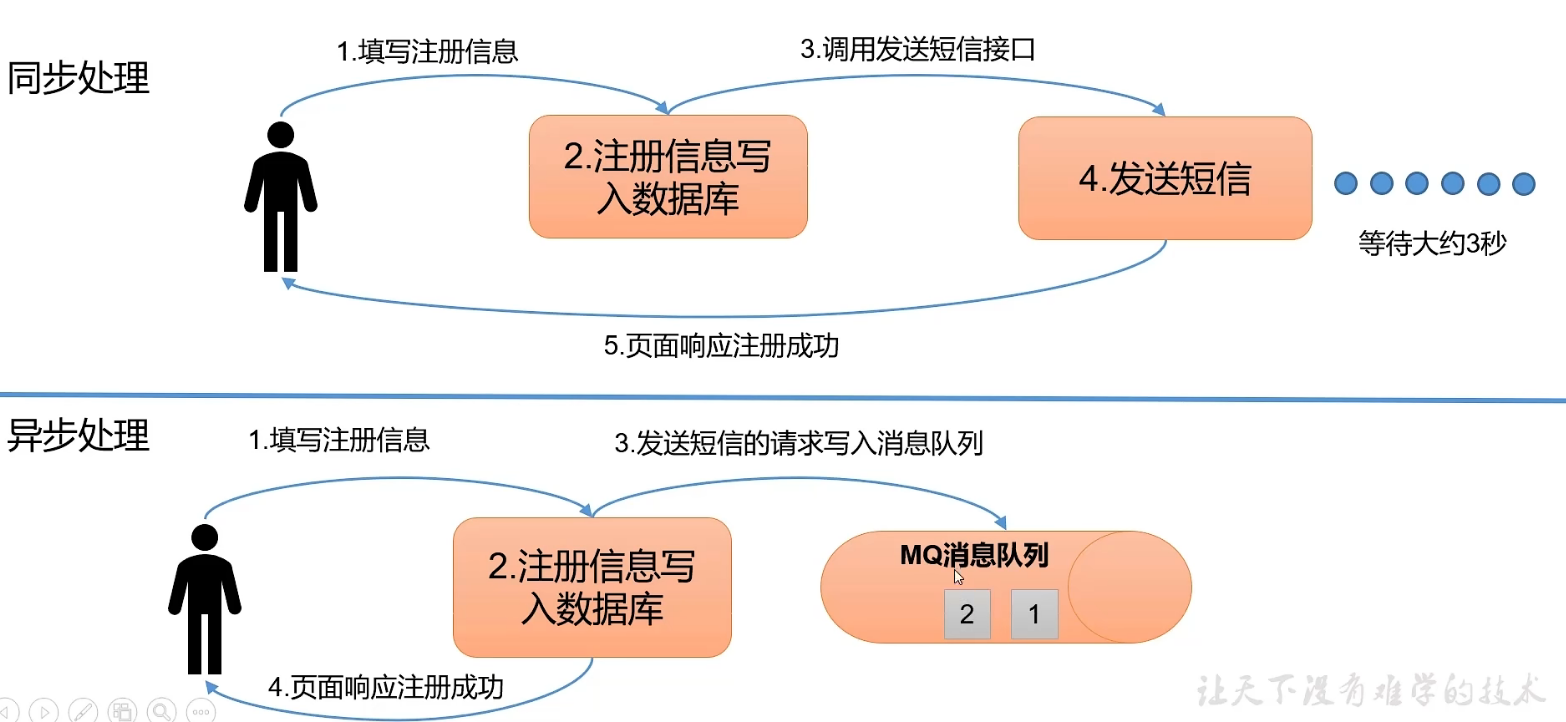
异步通信
允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理他们。
两种模式
点对点模式:
一个生产者对应于一个消费者
发布订阅模式
主流。
可以有多个topic
消费者消费数据之后不删除数据。
每个消费者相互独立,都可以消费到数据。
二、基础架构
简介
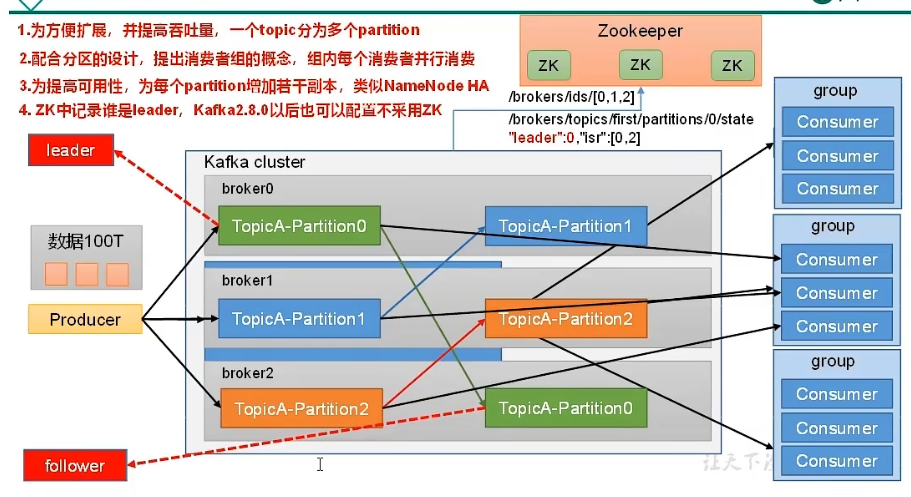
为方便扩展,提高吞吐量,一个topic分为多个partition
这是分区的方式。
比如100T的数据要发往一个topic,这个topic可以进行分区。
配合分区的设计,提出消费者组的概念,组内每个消费者并行消费。
一个broker就是集群里的一台服务器。
每个消费者负责一个partition的数据的消费。
一个消费者组负责一个topic的消费。
一个消费者组有多个消费者。
一个topic可以有多个partition,分别在不同的broker上。
生产者发送数据就是发送给broker,即服务器。
一个partition的数据只能由一个消费者来进行消费。
如果一个分区的数据由多个消费者来进行消费,就容易产生数据安全问题。
也就是说,一个topic可以分为多个partition(也就是说一个topic对应于一个broker集群),每个partition由一个消费者进行消费,几个partition就对应于几个消费者,这些消费者组成一个消费者组,一个topic就对应于一个消费者组即多个消费者。
所以不要理解为一个topic的数据被消费者组的消费者并行消费会产生安全问题,因为topic分了区。
为提高可用性,为每个partition增加若干副本
zookeeper会存储kafka集群,哪些服务器上线了,记录服务器节点运行的状态
记录每一个partition,谁是leader
kafka2.8.0以后也可以配置不采用zookeeper
分区数大于一个组里消费者数量时,有的消费者对应多个分区,当分区数等于消费者数的时候,每个消费者对应于一个分区。
概念
topic
主题。每条发布到kafka的消息都有一个类别,这个类别被称为topic。
物理上不同topic的消息分开存储,一个topic的消息也不并不是存储在一台服务器上。
逻辑上一个topic的消息虽然保存于一个或多个broker上,但用户只需指定消息的topic即可生产和消费数据而不需要关心数据存于何处。
partition(分区)
partition是物理上的概念,topic可以认为是逻辑上的概念。
每个topic包含一个或多个partition,创建topic时可以指定该topic对应的partition数量。
可以认为是真实存放数据的地方。
Replicas of partition(分区备份)
副本只是一个分区的备份,副本从不读取或写入数据,他们用于防止数据丢失。
broker
kafka集群包含一个或多个服务器,这种服务器节点被称为broker。
broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
kafka cluster
kafka 集群
producers
生产者。生产者是发送给一个或多个kafka主题的消息的发布者。生产者向kafka broker发送数据。生产者还可以向他们选择的分区发送消息。
consumers
消费者。每个消费者属于一个特定的consumer group。可为每个consumer指定group name,若不指定group name,则属于默认的group。
consumer group
消费者组。是逻辑上的概念,是kafka实现单播和广播两种消息模型的手段。同一个topic的数据,会广播给不同的消费者组,同一个group中的consumer,只有一个consumer能拿到这个数据。换句话说,对于同一个topic,每个group都可以拿到同样的所有数据,但是数据只能被group中的一个consumer消费。
group内的消费者可以使用多线程来实现。消费者组的消费者的数量,通常不超过partition的数量,且二者最好保持整数倍关系,因为kafka在设计时假定了一个partition只能被一个消费者消费。
三、快速入门
部署kafka集群
可以通过三台服务器的方式(三台虚拟机)
也可以通过一台linux服务器,三个服务端口的方式来模拟kafka集群。
我采用在一台机器上设置三个节点的方式。
为每个broker创建一个配置文件
cp config/server.properties config/server-1.properties cp config/server.properties config/server-2.properties修改server.properties
broker.id=0 listeners=PLAINTEXT://:9092 log.dir=/tmp/kafka-logs修改server-1.properties
broker.id=1 listeners=PLAINTEXT://:9093 log.dir=/tmp/kafka-logs-1修改server-2.properties
broker.id=2 listeners=PLAINTEXT://:9094 log.dir=/tmp/kafka-logs-2注意:
- broker.id是集群中每个节点的唯一且永久的名称,因为我们是在同一个机器上运行这些文件,所以为了避免端口冲突和数据覆盖,我们必须在以上配置文件中重写端口和日志目录。
先启动zookeeper
再依次启动三个节点的kafka即可。启动kafka,分别通过指定三个节点的配置文件。
启动kafka
启动zookeeper
./zookeeper-server-start.sh config/zookeeper.properties启动kafka
./kafka-server-start.sh -daemon ../config/server.properties现在kafka3.0版本不依赖zookeeper了,可以通过kafka-kraft模式启动,不依赖zookeeper
停止kafka
./kafka-server-stop.sh
kafka脚本
这里的kafka脚本都是指的kafka服务启动后,客户端连接上kafka服务器之后进行的操作。
topic脚本
kafka-topic.sh
| 参数 | 描述 |
|---|---|
| --bootstrap-server <String:server to connect to> | 连接的kafka broker主机名称和端口号 |
| --topic <String: topic> | 操作的topic名称 |
| --create | 创建主题 |
| --delete | 删除主题 |
| --alter | 修改主题 |
| --list | 查看所有主题 |
| --describe | 查看主题详细描述 |
| --partitions | 设置分区数 |
| --replication-factor | 设置分区副本 |
| --config | 更新系统默认的配置 |
查看当前服务器中的所有topic
./kafka-topics.sh --bootstrap-server xxxxx:9092 --list创建topic
./kafka-topics.sh --bootstrap-server xxxxx:9092 --topic first --create --partitions 1 --replication-factor 1这条命令要想执行成功,首先分区数不能超过broker数,broker实际上就是部署kafka集群的多台服务器。而分区是物理上的概念,实际上就对应于服务器,topic是逻辑上的概念,一个topic对应于多个partition,这多个partition就分别对应于这多台服务器。
分区副本replication-factor也不能超过broker数。
可以看上面的kafka架构图。
查看topic详细信息
./kafka-topics.sh --bootstrap-server xxxxx:9092 --topic first --describe可以看到是集群部署的方式而不是单点的方式。
[root@gpfs_node2 bin]# ./kafka-topics.sh --bootstrap-server xxxxx:9092 --topic first --describe Topic: first TopicId: AD3nEG3YQmGI-8CJZGyc1A PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824 Topic: first Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1修改分区
./kafka-topics.sh --bootstrap-server 192.168.15.106:9092 --topic first --alter --partitions 3修改分区,分区只能增多不能减少
[root@gpfs_node2 bin]# ./kafka-topics.sh --bootstrap-server 192.168.15.106:9092 --topic first --describe Topic: first TopicId: AD3nEG3YQmGI-8CJZGyc1A PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824 Topic: first Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1 Topic: first Partition: 1 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2 Topic: first Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
生产者脚本
kafka-console-producer.sh
./kafka-console-producer.sh --bootstrap-server xxxx:9092 --topic first
消费者脚本
kafka-console-consumer.sh
./kafka-console-consumer.sh --bootstrap-server xxxx:9092 --topic first
--from-beginning 是把历史数据也消费,不加这个参数的话,那么就是增量的消费数据,比如消费者在启动之前,生产者已经向指定broker发送消息a了,如果不加这个参数,是消费不到这条数据a的。
四、kafka生产者
生产者发送消息流程
一个分区会创建一个队列。
batch.size
只有数据积累到batch.size之后,sender线程才会发送数据,默认16k。
linger.ms
如果数据迟迟未达到batch.size,sender线程等待linger.ms设置的时间,到了之后就会发送数据,默认值是0ms,表示没有延迟。
以上两个配置在producer.properties里面进行配置。
这两个配置会影响kafka的吞吐量。
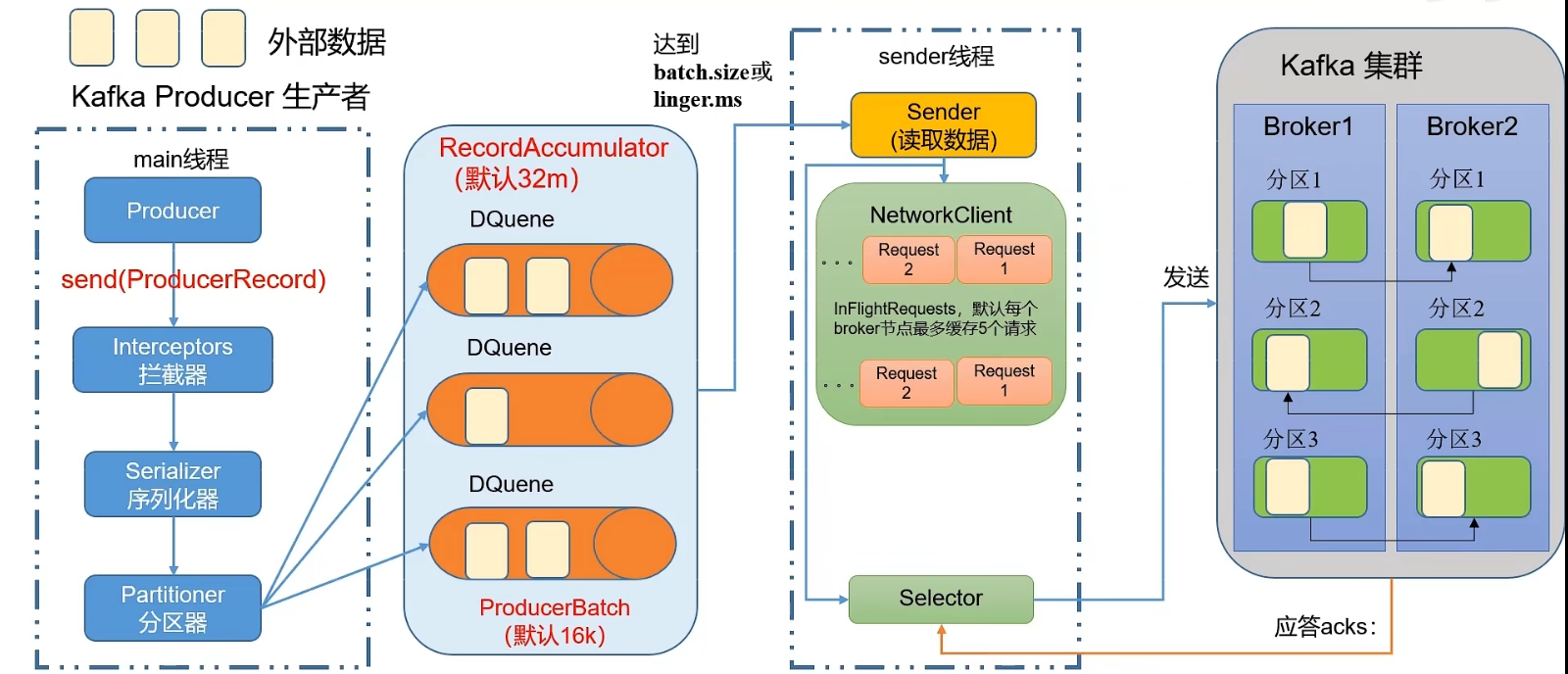
kafka集群收到sender线程发送过来的数据之后,会有应答acks。
acks:
- 0:生产者发送过来的数据,不需要等数据落盘应答。
- 1:生产者发送过来的数据,Leader收到数据后应答。
- -1:生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答,等价于all。
异步发送
概念
异步发送指的是外部数据发送到RecordAccumulator里,不必等待RecordAccumulator的这批数据成功发送到kafka broker。
达到batch.size或linger.ms后,sender线程去读取数据并发送请求给broker,发送数据给broker。
而异步发送不会等待sender线程去读取数据,发送数据给kafka。
异步的意思就是外部数据发送到RecordAccumulator这个过程和sender线程发送数据到broker这个过程,两个过程之间是异步的。
发后即忘
代码实现
initKafkaProducer
// 这里可以采用spring的JavaConfig public class KafkaProducerConfig { public static KafkaProducer<String, String> initKafkaProducer() { Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "xxx:9092,xxx:9093"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties); return kafkaProducer; } }Producer
public class Producer { public void sendDataToKafka() { //1. 创建kafka生产者对象 KafkaProducer<String, String> kafkaProducer = KafkaProducerConfig.initKafkaProducer(); //2.发送数据 try { for (int i = 0; i < 5; i++) { kafkaProducer.send(new ProducerRecord<>("first", "testKey", "eeeee" + i)); } } catch (Exception e) { e.printStackTrace(); } finally { //3.关闭资源 kafkaProducer.close(); } } }JavaConfig
spring本来是使用XML配置文件作为容器配置文件,spring的核心就是容器,IOC、AOP,其中IOC(控制反转)就依赖于容器,就是我们所需要用到的对象不在代码里通过new的方式或其他方式自己创建了,而是交给spring applicationContext容器对象统一管理,spring会读取applicationContext配置文件,读取此配置文件的目的是为了创建容器对象,而在配置文件中又进行了JavaBean的配置,就是我们所需要用到的对象的配置,所以在创建好容器对象的同时,也创建好了对象,并放到了容器中。spring容器底层是concurrent hashmap。
而
JavaConfig就简化了这个步骤,我们不再需要编写XML配置文件,不需要通过XML配置文件的方式来实现IOC,而是通过@Configuration注解!在SpringBoot框架中,通常使用@Configuration注解定义一个配置类,springboot会自动扫描和识别配置类,从而替换传统spring框架中的xml配置文件。
@Bean注解,其返回值对象会作为组件添加到了spring容器,如果不指定对象的名称,默认方法名是对象在容器中的名字即id
所以第1点的代码可改成如下的JavaConfig形式:
@Configuration public class KafkaProducerConfig { @Bean(destroyMethod = "close") public KafkaProducer<String, String> initKafkaProducer() { Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "xxx:9092,xxx:9093"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties); return kafkaProducer; } }将对象注入到容器中之后,通过@Autowired注入就可以直接使用了。
异步回调
在
send()方法里指定一个 Callback 回调函数。代码
public class Producer { public void sendDataToKafka() { //1. 创建kafka生产者对象 KafkaProducer<String, String> kafkaProducer = KafkaProducerConfig.initKafkaProducer(); //2.发送数据 try { for (int i = 0; i < 5; i++) { kafkaProducer.send(new ProducerRecord<>("first", "testKey", "eeeee" + i), new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e == null) { System.out.println("topic: " + recordMetadata.topic() + " partition: " + recordMetadata.partition()); } } }); } } catch (Exception e) { e.printStackTrace(); } finally { //3.关闭资源 kafkaProducer.close(); } } }
同步发送
同步发送指的是发送到RecordAccumulator的外部数据,这批数据必须发送到broker,发送完毕之后,外部数据才会再发送到RecordAccumulator。
也就是消息必须成功发送到kafka broker之后,即kafka有响应之后,才会继续发送数据。